
工作中负责了一个和数据源交互很重的模块,并独立开启重写任务。其中一个很重要的变化就是将 15 年源代码中所采用的一代 DBCP 换成 HikariCP。因为这个模块与池的交互实在太深了,所以我必须要比常人对 HikariCP 有更好的理解,所以想写一篇纪要进行总结,文章很多内容来自《HikariCP数据库连接池实战》。
DB Pool 基础
为何需要连接池
以访问MySQL为例,执行一个SQL语句的完整TCP流程共经历:TCP三次握手建立连接、MySQL三次握手认证、SQL语句执行、MySQL关闭、TCP四次挥手关闭连接5个步骤。
不用连接池的主要问题:
- 创建连接和关闭连接的过程比较耗时,并发时系统会变得很卡顿。
- 数据库同时支持的连接总数是有限的,如果并发量很大,那么数据库连接的总数就会被消耗光,增加数据库的负载,新的数据库连接请求就会失败。这样就会极大地浪费数据库的资源,极易造成数据库服务器内存溢出、宕机。
- 为了执行一条SQL,却产生了很多我们并不关心的网络IO。
- 应用如果频繁地创建连接和关闭连接,会导致JVM临时对象较多,GC频繁。
- 频繁关闭连接后,会出现大量TIME_WAIT的TCP状态(在2个MSL之后关闭),这点很棘手。
- 应用的响应时间及QPS较低。
因此,使用连接池的优点就是相对的:资源重用节省开销、系统能有更快的相应、可以进行统一的连接管理、更便于进行系统调优。
数据库连接池原理
- 在系统初始化的时候,在内存中开辟一片空间,将一定数量的数据库连接作为对象存储在对象池里,并对外提供数据库连接的获取和归还方法。
- 用户访问数据库时,并不是建立一个新的连接,而是从数据库连接池中取出一个已有的空闲连接对象;使用完毕归还后的连接也不会马上被关闭,而是由数据库连接池统一管理回收,为下一次借用做好准备。
- 如果由于高并发请求导致数据库连接池中的连接被借用完毕,其他线程就会等待,直到有连接被归还。
- 数据库连接池还可以通过设置其参数来控制连接池中的初始连接数、连接的上下限数,以及每个连接的最大使用次数、最大空闲时间等,也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
连接的创建、获取和归涉及两项技术:一是连接使用List之类的集合进行初始化、装载和归还,二是使用动态代理来把资源归回给List集合。而HikariCP之所以这么快,也主要是将这两项技术做到了极致。
连接池的构成
一款商用的数据库连接池除了连接池的建立和释放两大核心功能外,还支持:
- 并发(锁性能优化乃至无锁)
- 连接数控制(不同的系统对连接数有不同的需求)
- 监控(一些自身管理机制来监视连接的数量及使用情况等)
- 外部配置(各种主流数据库连接池官方文档最核心的部分)
- 资源重用(数据库连接池的核心思想)
- 检测及容灾(面对一些网络、时间等问题的自愈)
- 多库多服务(如不同的数据库、不同的用户名和密码、分库分表等情况)
- 事务处理(对数据库的操作符合ALL-ALL-NOTHING原则)、定时任务(如空闲检查、最小连接数控制)
- 缓存(如PSCache等避免对SQL重复解析)
- 异常处理(对JDBC访问的异常统一处理)
- 组件维护(如连接状态、JDBC封装的维护)等。
JDBC
简述
JDBC API是Java编程语言与各种数据库之间数据库无关连接的行业标准。JDBC API是一种执行SQL语句的API,JDBC驱动才是真正的接口实现,所有的网络逻辑和特定于数据库的通信协议都隐藏于、独立于供应商的JDBC API后面。Sun公司只是提供了JDBC API,每个数据库厂商都有自己的驱动来连接自己公司的数据库。
JDBC API采用了桥接的设计模式。JDBC接口相当于实现化角色接口,数据库厂商实现的驱动相当于具体实现化子类;应用程序相当于抽象化角色,内部持有一个实现化角色的对象。桥接模式将实现化和抽象化解耦,从而让两个部分可以沿着不同的方向拓展,只要遵循接口即可。
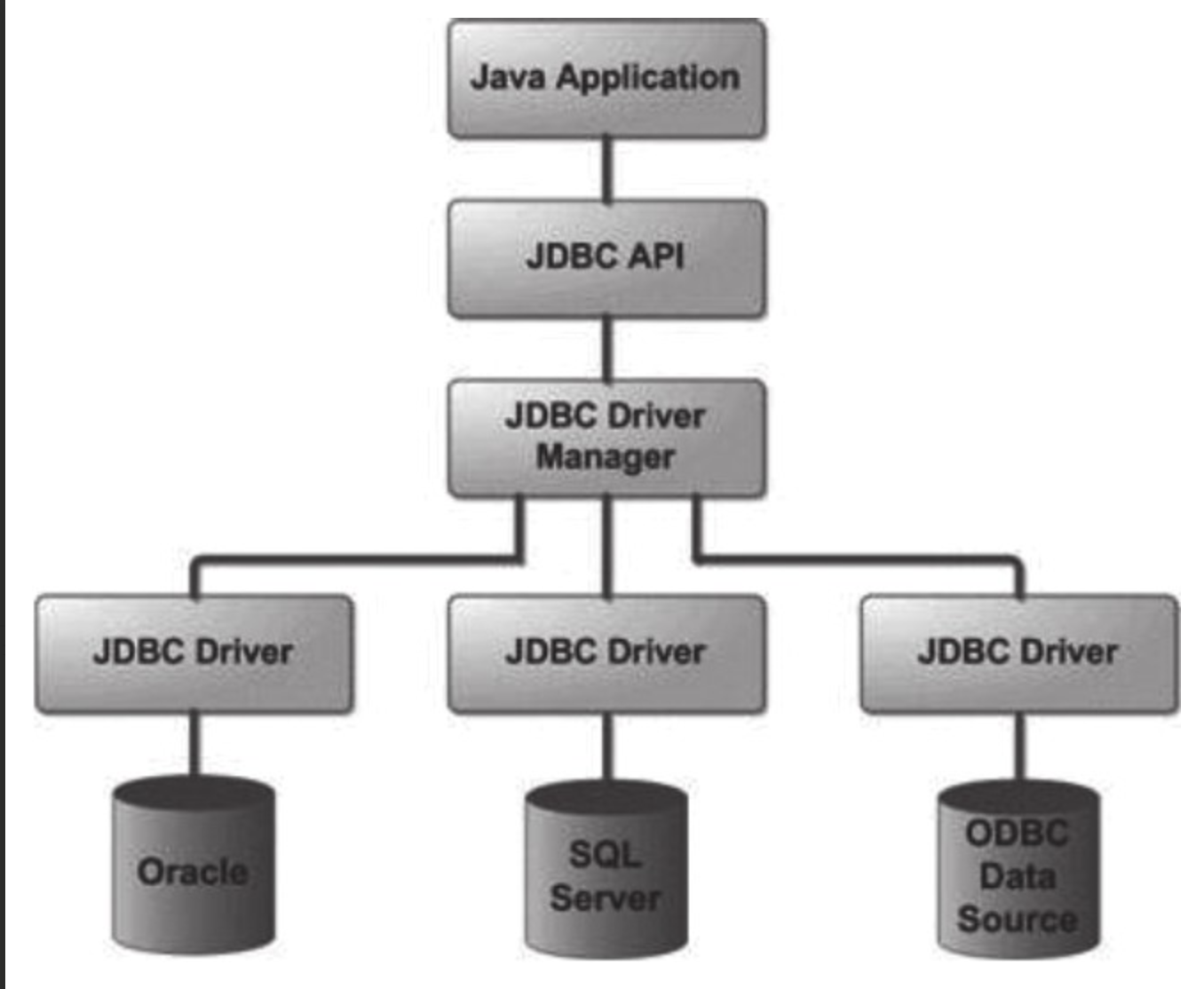
JDBC API主要位于JDK中的java.sql包中,扩展的内容位于javax.sql包中。了解JDBC,关注点更多的还是java.sql.*包,在这个包里,有4个核心接口(Driver、Connection、Statement和ResultSet)和两个核心类(DriverManager和SQLException)。
Statement关闭会导致ResultSet关闭,但是Connection关闭却不一定会导致Statement关闭。在数据库连接池里,Connection关闭并不是物理关闭,只是归还连接池,所以Statement和ResultSet有可能被持有,并且实际占用相关的数据库的游标资源。所以在关闭Connection前,需要关闭所有相关的Statement和ResultSet。这就是HikariCP作者所强调的JDBC的最基本的规范,也是他创造HikariCP的原因,数据库连接池一定不能违背这样的规则。最好方案就是顺序关闭ResultSet、Statement、Connection;在rs.close()和stmt.close()后面加上rs=null和stmt=null来防止内存泄漏。
Statement和PreparedStatement
PreparedStatement在企业开发中被强烈推荐使用,原因主要有以下方面:
- Statement会频繁编译SQL。如果JDBC驱动支持的话(一般来说数据库系统库系统初次分析、编译时会对查询语句做最大的性能优化),PreparedStatement可对SQL进行预编译,提高效率,预编译的SQL存储在PreparedStatement对象中。从这个意义上来说,PreparedStatement比Statement更快,使用PreparedStatement也可以降低生产环境的数据库负载。
- Statement对象编译SQL语句时,如果SQL语句有变量,就需要使用分隔符来隔开,如果变量非常多,就会使SQL变得非常复杂。PreparedStatement可以使用占位符,通过动态参数化的查询来简化SQL的编写。
- PreparedStatement可防止SQL注入。
JDBC的最佳实践
- 使用PrearedStatement,通过预编译的方式避免在拼接SQL时造成SQL注入,使用“?”或其他占位符等变量绑定的形式可以使用不同的参数执行相同的查询也能防止SQL注入。
- 禁用自动提交,这样可以将数据库操作放在一个事务中,而不是每次执行SQL语句都在执行结束时提交自己独立的事务。
- JDBC批处理可以降低数据库传输频率,进而提升性能。
- 使用列名而不是列序号获取ResultSet中的数据,避免invalidColumIndexError,从而提升程序的健壮性、可读性。
- 在Java 7中,可以通过Automatic Resource Management Block来自动关闭资源。要记得关闭所有的Connection、Statement等资源。
- 使用标准的SQL语句(如标准的ANSI SQL),避免数据库对SQL支持的差异。
JDBC与SPI
JDBC 4.0以前,开发人员还需要基于Class.forName(“xxx”)的方式来装载驱动,而JDBC 4.0基于SPI机制来发现驱动提供商,可以通过META-INF/services/java.sql.Driver文件里指定实现类的方式来暴露驱动提供者。开发者只需要编写一行代码,使用不同厂商的jar包,就可以轻松创建连接了。
1 | Connection conn = DriverManager.getConnection(URL,USER,PASSWORD); |
关于SPI
在Java中根据一个子类获取其父类或接口信息非常方便,但是根据一个接口获取该接口的所有实现类却没那么容易。有一种比较笨的办法就是扫描classpath下所有的class与jar包中的class,接着用ClassLoader加载进来,再判断是否是给定接口的子类。但是这种方法的代价太大,一般不会使用。根据这个问题,Java推出了ServiceLoader类来提供服务发现机制,动态地为某个接口寻找服务实现。当服务的提供者提供了服务接口的一种实现之后,必须根据SPI约定在META-INF/services/目录里创建一个以服务接口命名的文件,该文件里写的就是实现该服务接口的具体实现类。当程序调用ServiceLoader的load方法的时候,ServiceLoader能够通过约定的目录找到指定的文件,并装载实例化,完成服务的发现。
ServiceLoader是JDK6里面引进的一个特性,通过它可以具体实现代码的解耦,实现类似于IOC的效果。针对ServiceLoader还有一个特定的限制,就是具体实现类必须提供无参数的构造函数,否则ServiceLoader就会报错。
DriverManager的SPI实现
DriverManager 中有一个静态代码块:
1 | static { |
1 | private static void loadInitialDrivers() { |
MySQL的Driver实现在初始化的时候也是在 static 方法里就将自己的com.mysql.jdbc.Driver直接注册到了java.sql.DriverManager中。
1 | public class Driver extends NonRegisteringDriver implements java.sql.Driver { |